Проблемы с сетевой доступностью 5 февраля 2020 года
Резюме по инциденту с частичной или полной недоступностью сервисов Яндекс.Облака.
5 февраля 2020 года с 16:05 до 18:35 по Москве пользователи Яндекс.Облака испытывали сложности с доступом к сервисам Яндекс.Облака через консоль и API. Мы приносим свои извинения всем пользователям, кого затронул данный инцидент, и хотим рассказать подробнее о случившемся и мерах предотвращения повторения подобной ситуации в будущем.
Что произошло?
5 февраля в рамках проведения регулярных работ, направленных на повышение отказоустойчивости сервисов Яндекса, произошел сбой в работе внутреннего DNS, что в результате привело к недоступности ряда сервисов компании, в том числе Яндекс.Облака. Историю событий можно найти на странице инцидента.
Причины
В Яндексе проводятся регулярные регламентные работы, призванные повысить отказоустойчивость сервисов компании. Работы проводятся несколько раз в месяц. На время работ мы отключаем один из дата-центров, чтобы убедиться, что все сервисы, распределённые по нескольким дата-центрам, при максимальной нагрузке могут обслужить все запросы пользователей без падения качества. Работы организованы таким образом, что они не оказывают влияния на работу сервисов Яндекса, в том числе и Яндекс.Облака, и не затрагивают ресурсы и данные пользователей, размещенных в Яндекс.Облаке.
Отключение дата-центра проходит в несколько этапов:
- Сервисы уводят нагрузку в soft-режиме в другие дата-центры.
- L3-балансировщики перестают пускать на отключённый дата-центр внешний трафик.
- Производим проверку, что системы и сервисы не деградируют.
Если проверка прошла успешно, то отключаем сетевую связность между дата-центром, где проводятся регламентные работы, и всей остальной сетью Яндекса.
5 февраля регулярные учения были начаты согласно этому процессу:
- 16:00 — успешно перенаправили нагрузку в другие дата-центры.
- 16:03 — L3-балансировщики изолировали нужный дата-центр от внешнего трафика.
- 16:04 — замечаем проблемы с производительностью сервиса DNS в оставшихся дата-центрах.
Внутренний DNS-сервис Яндекса устроен следующим образом:
- Для отказоустойчивости у нас есть несколько ферм DNS-кэшей в разных дата-центрах.
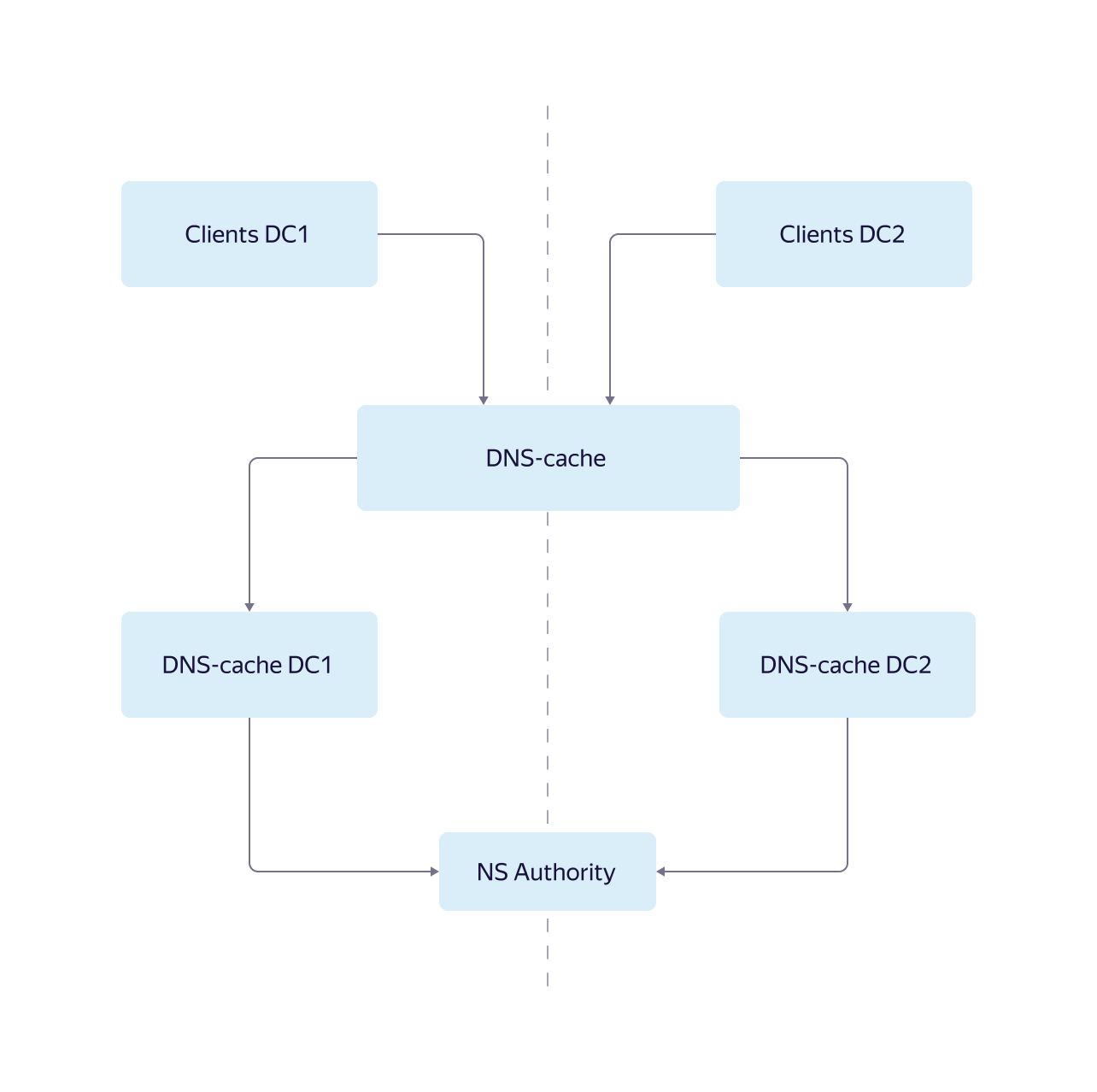
- В списке DNS-резолверов на серверах на первом месте стоит локальный кэш, на втором и третьем месте — фермы DNS-кэша. Когда в отключенном дата-центре L3-балансировщики перестают пускать внешний трафик, серверы из этого дата-центра при сохранившейся сетевой связности обращаются к DNS-кэш в другие дата-центры.
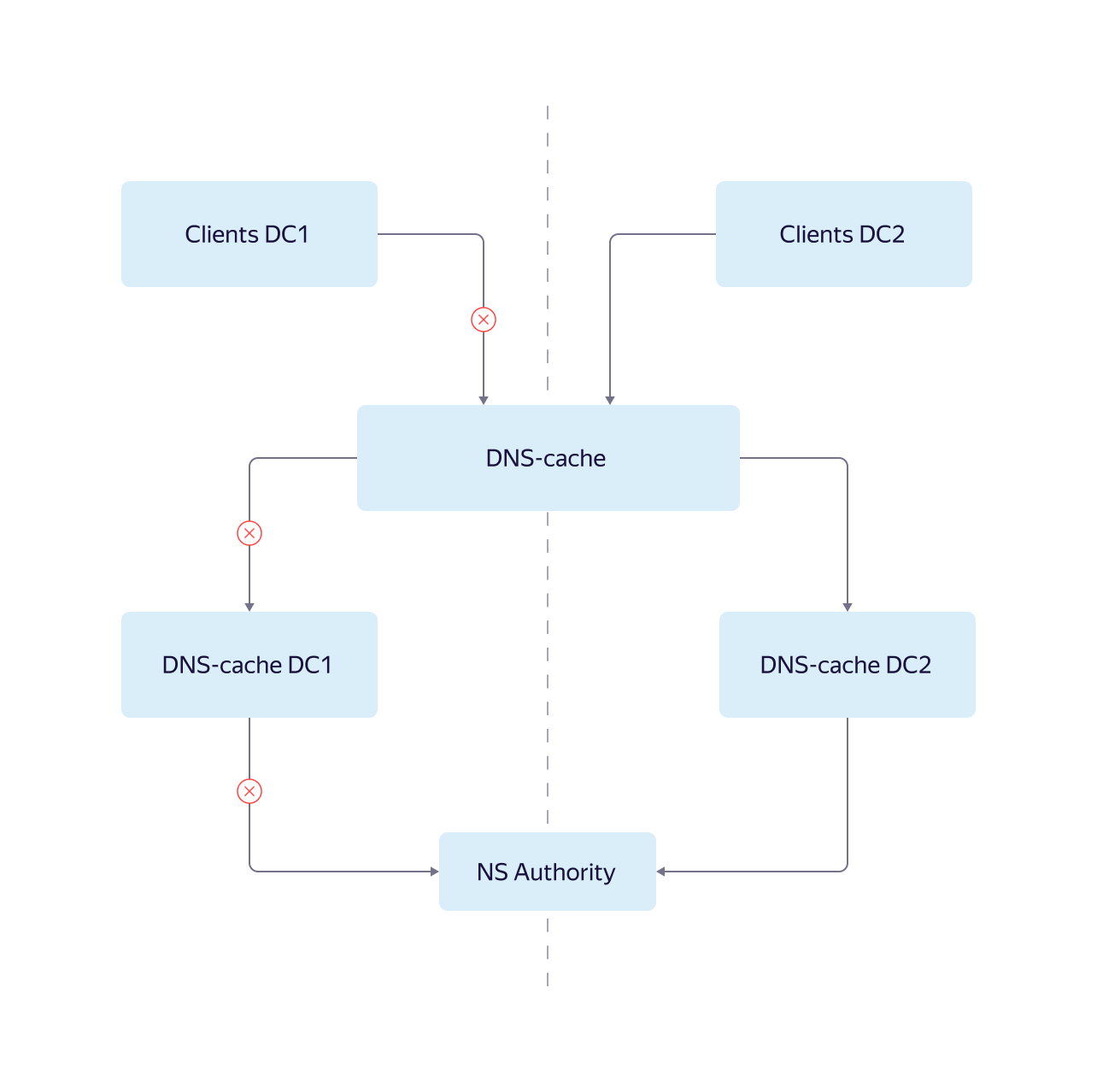
- Из-за особенностей архитектуры DNS-кэш активных дата-центров не имеет информации о нужных записях, которые есть в кэшах отключенного дата-центра, и усиленно обращается на фермы авторитетных серверов — серверов, которые хранят всю информацию о зоне адресов, за которую они отвечают.
5 февраля нагрузка была выше, чем в рамках предыдущих работ, и фермы не выдержали: увеличилось время ответов и выросло число перезапросов. Эффект резко возросшего количества запросов к DNS-кэшу также усилился из-за того, что один из крупных внутренних потребителей на время работ по ошибке не снизил и не убрал свою нагрузку. Это окончательно перевело авторитетные серверы в нерабочее состояние.
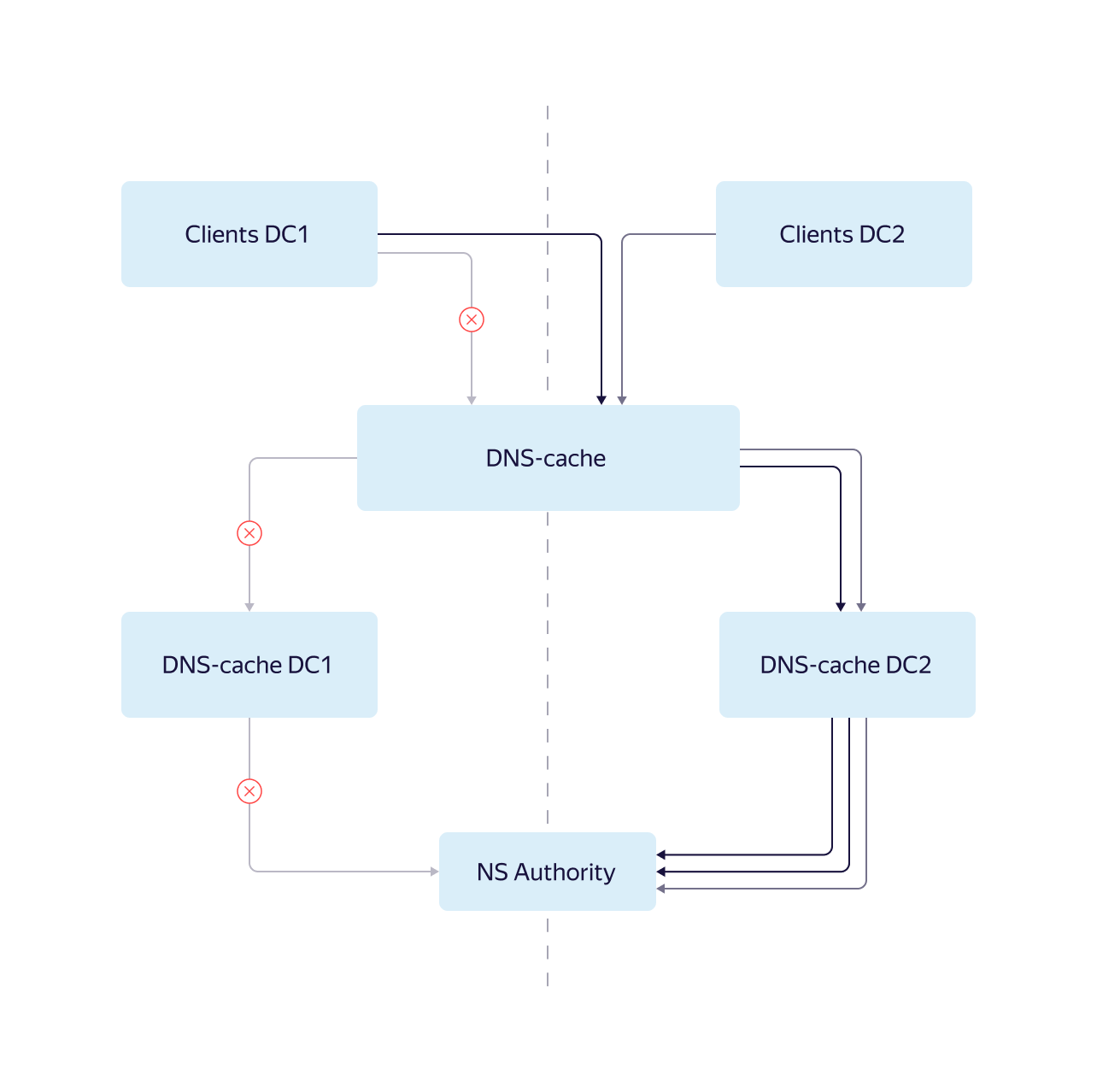
Для оперативного устранения неполадок к 17.45 мы нарастили ферму авторитетных DNS-серверов и отключили внутренних потребителей в дата-центре, где планировались работы. К 18.35 ситуацию удалось полностью стабилизировать.
Меры для предотвращения повторения подобной ситуации в будущем:
- Мы увеличим количество DNS-серверов, которые обслуживают внутренние и внешние запросы.
- Мы изменим архитектуру системы DNS-кэширования так, чтобы повысить ее производительность.
- Мы разделим DNS-фермы авторитетных серверов для внешних и внутренних пользователей и увеличим их производительность. Для внутренних высоконагруженных сервисов будут запущены выделенные DNS фермы.
- Все зоны адресов Яндекс.Облака будут иметь собственные независимые DNS-фермы авторитетных серверов.